import os
import numpy as np
import geopandas as gpd
import xarray as xr
import rioxarray as rioxr
from shapely import Point
import matplotlib.pyplot as plt22 Raster manipulation I
In this lesson we will learn how to perform some global and local operations on our raster. We will also go over customizations for plotting raster data and review the Python for loop.
22.1 Data
We will use data from the Copernicus Digital Elevation Model (DEM). This dataset ris based on radar satellite data measuring the relative height of Earth’s surface. The Copernicus DEM is available at 30-meter and 90-meter resolution. The data prepared for this class is a tile of 1°x1° latitude/longitude form the Copernicus DEM at 90-meter resolution over the Grand Canyon in the US. Each pixel represents vertical units measured in meters. The data was accessed via the Microsoft’s Planetary Computer Copernicus DEM GLO-30 data repository
Click here to access the Copernicus DEM complete product Handbook.
22.2 Import data
Let’s start by loading the libraries we’ll use:
Exercise
- Use
osto createa file path to the ‘grand_canyon_DEM.tif’ file and import the raster into a variable calledgc. - Plot the raster, check the CRS, and create a histogram with updated bin numbers.
Solution
Loading our dataset:
# load Grand Canyon DEM data
data_path = os.path.join(os.getcwd(),'data','grand_canyon_DEM.tif')
gc = rioxr.open_rasterio(data_path)
gc<xarray.DataArray (band: 1, y: 1200, x: 1200)>
[1440000 values with dtype=float32]
Coordinates:
* band (band) int64 1
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 37.0 37.0 37.0 37.0 ... 36.0 36.0 36.0 36.0
spatial_ref int64 0
Attributes:
AREA_OR_POINT: Point
scale_factor: 1.0
add_offset: 0.0A brief exploration of our dataset:
# exploratory plot
gc.plot()<matplotlib.collections.QuadMesh at 0x149fbc790>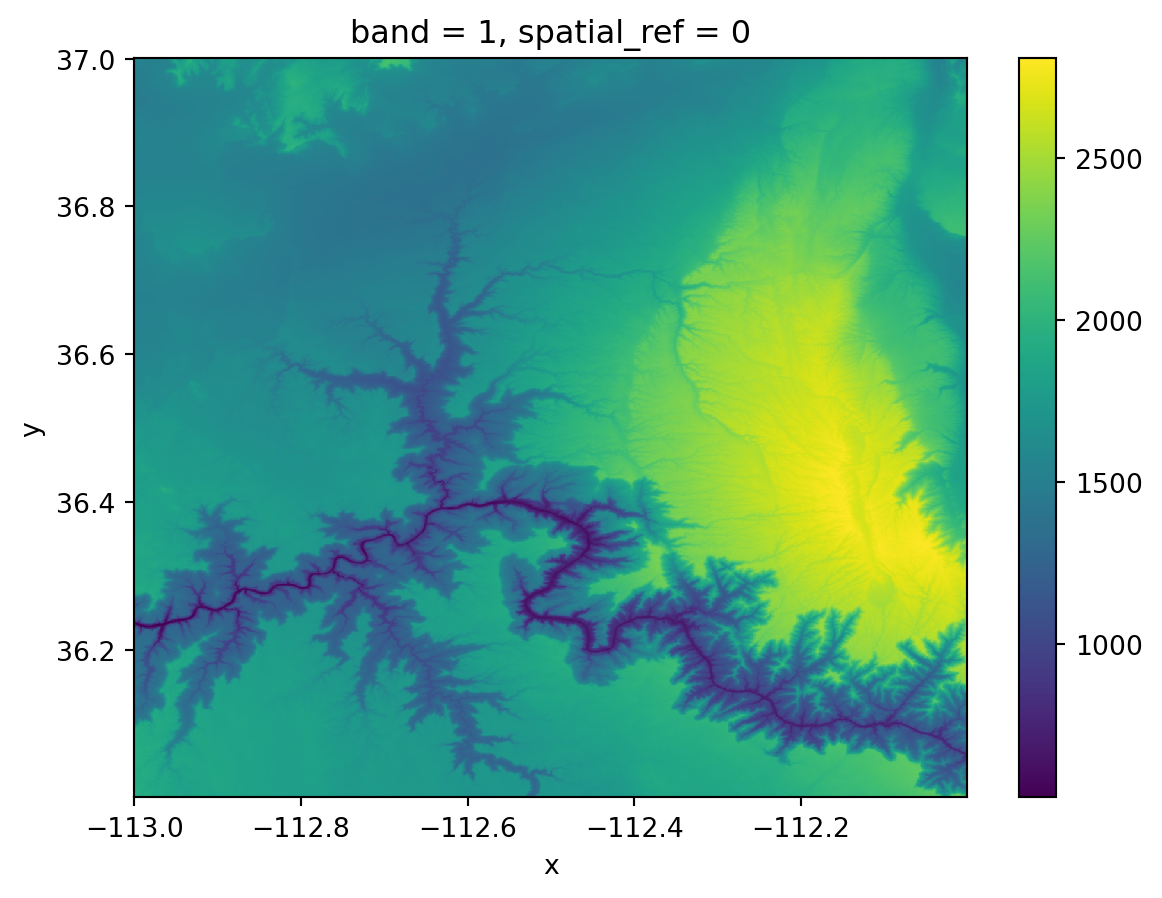
Getting the coordinate reference system (CRS):
# check the raster's CRS
gc.rio.crsCRS.from_epsg(4326)Check distribution of elevation values:
# plot histogram of elevation values
# get bin values output on "disposable" variable _
_ = gc.plot.hist(bins=50)
_
Notice in the previous line of code we used the underscore _ to capture the output of the histogram. The underscore _ is often used in Python to name a “disposable” variable we will not use in the future.
22.3 Dropping a dimension: squeeze() and drop()
Notice that our raster has an unnecessary extra dimension: band.
gc<xarray.DataArray (band: 1, y: 1200, x: 1200)>
array([[[1539.077 , 1540.6287, ..., 1557.3568, 1552.1139],
[1537.7278, 1538.4757, ..., 1559.02 , 1555.9811],
...,
[1947.7771, 1943.48 , ..., 1956.2341, 1966.1176],
[1938.799 , 1933.4049, ..., 2055.6274, 2039.6412]]], dtype=float32)
Coordinates:
* band (band) int64 1
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 37.0 37.0 37.0 37.0 ... 36.0 36.0 36.0 36.0
spatial_ref int64 0
Attributes:
AREA_OR_POINT: Point
scale_factor: 1.0
add_offset: 0.0This is making this datsets three-dimensional when it is not needed. We can clean this xarray.DataArray a bit by:
using the
squeeze()method. If we don’t pass any parameters, thensqueeze()gets rid of all dimensions with length one, and thengetting rid of the associated coordinates for this dimension. We can do this using the
xarray.DataArraydrop()method and specifying the name of the coordinates we want to remove, in this case ‘band’.
Let’s do this:
# original dimensions and coordinates
print(gc.dims, gc.coords,'\n')
# remove length 1 dimension (band)
gc = gc.squeeze()
print(gc.dims, gc.coords,'\n')
# remove coordinates associated to band
gc = gc.drop('band')
print(gc.dims, gc.coords)('band', 'y', 'x') Coordinates:
* band (band) int64 1
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 37.0 37.0 37.0 37.0 ... 36.0 36.0 36.0 36.0
spatial_ref int64 0
('y', 'x') Coordinates:
band int64 1
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 37.0 37.0 37.0 37.0 ... 36.0 36.0 36.0 36.0
spatial_ref int64 0
('y', 'x') Coordinates:
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 37.0 37.0 37.0 37.0 ... 36.0 36.0 36.0 36.0
spatial_ref int64 022.4 Global information
To get a better sense of our raster data we can apply common numpy functions to extract information from the xarray.DataArray underlying np.array.
For example, we can get the maximum across all the xarray.DataArray’s values by using the max() method:
# get the maximum elevation value (get an xarray.DataArray)
gc.max()<xarray.DataArray ()>
array(2808.8005, dtype=float32)
Coordinates:
spatial_ref int64 0Notice that the output for this method is another xarray.DataArray. In general, methods that reduce or subset an xarray.DataArray will always return another xarray.DataArray. To extract the value from a 1x1 xarray.DataArray as a number we use the .item() method:
# get the maximum elevation value as a number
gc.max().item()2808.80053710937522.5 f-strings
So far we have printed variables using string concatenation inside the print() function. This means that we write commas between every string and variable we want to print, and then the print function concatenates these into a single string. For example:
# minimum elevation
# print via concatenation
print("Minimum elevation: ", gc.min().item())Minimum elevation: 528.0Another popular way of mixing strings and variables in print statements is by creating an f-string which stands for “formatted string”. The simplest syntax for an f-string is:
f" some text {replace}"where replace can be a variable, an expression, or a function or method call. For example:
# f-string with mean elevation
f"Mean elevation: {gc.mean().item()}"'Mean elevation: 1764.859375'We just created a string replacing the value inside the curly brackets {}. Notice the computation is occurring in real time as the string gets made and there’s no need to define any extra variables.
One of the advantages of using f-strings is that they offer customization for formatting the output, without the need to use extra functions. For example, if we want to print the median value of our raster rounded to two decimals we can do:
# median elevation, rounded to two decimals
# print via f-string formatting
print(f"Median elevation: {gc.median().item():.2f}")Median elevation: 1726.15Some extra resources about using f-string formatting: - Real Python - Python’s F-String for String Interpolation and Formatting - Python documentation- Format Specification Mini-Language
22.6 Aggregation: coarsen()
Let’s go back to our raster. Rasters with high spatial resolution can offer great insight into fine-scale patterns, but can also be challenging to process due to their size. In these cases, it can be useful to use an aggregation method to spatially downsample and obtain a raster with a coarser resolution.
To spatially downsample an xarray.DataArray we use the coarsen() method followed by an aggreagator function. The general syntax to coarsen a 2-dimensional :
xdataarray.coarsen(x=x_winside, y=y_winside).aggr()where:
xdataarrayis a 2-dimensionalxarray.DataArraywith dimensionsxandy.xandyare the names dimensions of thexarray.DataArray(these could have other names likelon/lat)x_winsideandy_winsideare the dimensions of the window used to make the aggregation.aggr()is an aggregator function, this is the function which will be applied to each window. Examples aremin(),max(),sum()andmean().
Example
Suppose we want to coarsen our Grand Canyon elevation raster from 1200x1200 pixels to a raster of 60x60 pixels where by calculating the maximun at each window. Remember the windows are non-overlapping, so we will obtain one pixel per window. A quick division tells us that to got from 1200x1200 to 60x60 we will need to use a 20x20 window. The aggregator function on each of this window will be max(). Our call looks like this:
# coarsen to a 60x60 raster calculating the maximum value in each window
gc_coarse = gc.coarsen(x=20,y=20).max()
gc_coarse<xarray.DataArray (y: 60, x: 60)>
array([[1543.2703, 1536.2582, 1905.042 , ..., 1752.2424, 1870.8307,
1841.452 ],
[1511.454 , 1548.8307, 1944.3944, ..., 1782.2041, 1881.2681,
1925.4775],
[1508.7517, 1549.587 , 1666.655 , ..., 1762.2898, 1769.2545,
1974.3519],
...,
[1944.1821, 1919.3833, 1891.5801, ..., 1898.1538, 1619.7513,
1548.6755],
[1932.8036, 1924.7229, 1894.8312, ..., 1732.8718, 1707.6681,
1720.0978],
[1948.1812, 1923.23 , 1898.333 , ..., 2224.2847, 2248.0986,
2272.8677]], dtype=float32)
Coordinates:
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 36.99 36.98 36.96 36.94 ... 36.06 36.04 36.03 36.01
spatial_ref int64 0
Attributes:
AREA_OR_POINT: Point
scale_factor: 1.0
add_offset: 0.0# inspect old and coarsened resolution
print(f"old resolution: {gc.rio.width}x{gc.rio.height}")
print(f"coarse resolution: {gc_coarse.rio.width}x{gc_coarse.rio.height}")
gc_coarse.plot()old resolution: 1200x1200
coarse resolution: 60x60<matplotlib.collections.QuadMesh at 0x14aae6550>
Exercise
Downsample the elevation raster into a 240x240 raster by taking the average over windows of the appropriate size.
Use an f-string to check whether the spatial bounds of the rasters have changed.
Solution
Decrese resolution:
# coarsen to a 240x240 raster calculating the mean in each window
gc_coarse_mean = gc.coarsen(x=5,y=5).mean()
gc_coarse_mean<xarray.DataArray (y: 240, x: 240)>
array([[1535.3939, 1535.8931, 1532.352 , ..., 1625.2432, 1551.3588,
1563.1356],
[1521.945 , 1521.6814, 1521.8566, ..., 1584.5142, 1627.8928,
1593.6633],
[1509.4419, 1511.2308, 1509.6614, ..., 1609.3103, 1700.0897,
1650.7216],
...,
[1932.3878, 1923.3806, 1905.713 , ..., 1738.6489, 1604.5614,
1512.9637],
[1941.5138, 1928.9819, 1911.285 , ..., 2034.8147, 1858.8019,
1736.1644],
[1938.8174, 1919.249 , 1919.581 , ..., 2261.3406, 2198.5483,
2007.7867]], dtype=float32)
Coordinates:
* x (x) float64 -113.0 -113.0 -113.0 ... -112.0 -112.0 -112.0
* y (y) float64 37.0 36.99 36.99 36.99 ... 36.02 36.01 36.01 36.0
spatial_ref int64 0
Attributes:
AREA_OR_POINT: Point
scale_factor: 1.0
add_offset: 0.0gc_coarse_mean.plot()<matplotlib.collections.QuadMesh at 0x14ad3dfd0>
Check spatial bounds:
print(f"old spatial bounds: {gc.rio.bounds()}")
print(f"coarse resolution: {gc_coarse_mean.rio.bounds}")
gc_coarse_mean.plot()old spatial bounds: (-113.00041666666667, 36.000416666666666, -112.00041666666667, 37.000416666666666)
coarse resolution: <bound method XRasterBase.bounds of <rioxarray.raster_array.RasterArray object at 0x14ad8a7d0>><matplotlib.collections.QuadMesh at 0x14af33450>